Procesamiento del Lenguaje Natural¶
Introducción al PLN¶
El procesamiento del lenguaje natural es un campo muy amplio, que abarca diversas áreas, y relaciona varios campos de la técnica y la lingüística. Siguiendo la línea del test de Turing, en 1954 se llevó a cabo el test de Georgetown que supuso la traducción automática de unas 60 oraciones del ruso al inglés de manera exitosa.
Definición
El procesamiento del lenguaje natural estudia las relaciones del lenguaje entre los seres humanos y las máquinas.
Tras ello hubo un parón en el desarrollo de esta disciplina, debido a limitaciones del hardware, que perduraría hasta la década de 1980.
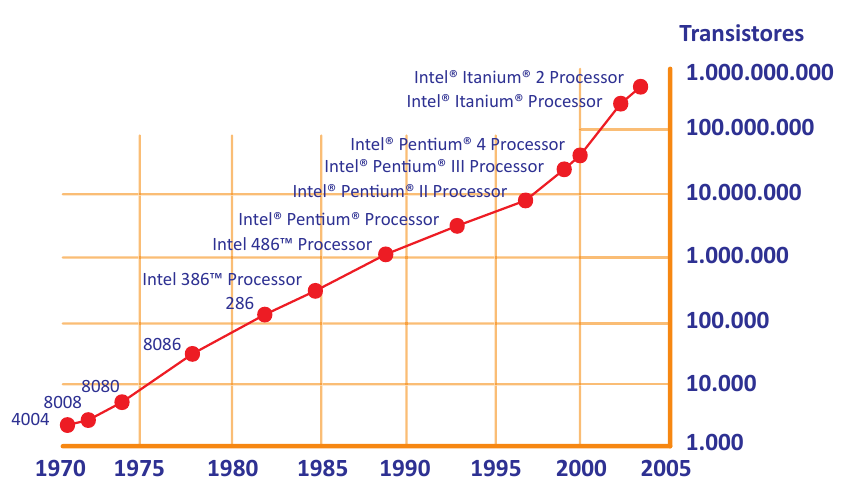
La ley de Moore indica que cada 2 años, desde 1970, se duplica el número de transistores en un microprocesador, lo que directamente expresa un aumento en términos de potencia de computación. Ese incremento de potencia, al igual que en otras disciplinas de la inteligencia artificial, como la visión artificial, ha sido lo que ha posibilitado el estado alcanzado actualmente por la técnica.
El procesamiento del lenguaje natural implica necesariamente de la unión de dos áreas: el área asociada a la máquina y el área relacionada con el ser humano. Esta última comporta la forma actual de comunicación entre seres humanos, ya que, si el objetivo es tratar de que una máquina se comunique con un ser humano, y viceversa, es necesario el estudio formal de la manera en la que se comunica una persona, y es precisamente en este punto donde entra en juego la lingüística como disciplina de estudio.
Más información
A lo largo de la historia de la humanidad ha habido distintos tipos de teorías lingüísticas comunes a varios idiomas, siendo muy común la de Noam Chomsky (por ejemplo, la gramática de constituyentes/transformacional).
Definición
El objetivo general de los sistemas de Procesamiento del Lenguaje Natural (PLN) es el tratamiento de la lengua a fin de ser interpretada y/o producida a la manera en la que lo hacemos los seres humanos (COMPRENSIÓN). Es una tarea de gran complejidad.
Un corpus es un conjunto de palabras (un texto) de una lengua y se emplea para formar un diccionario, pero no en el sentido de documento donde se explica o definen palabras, sino como concepto de conjunto de palabras de una lengua. Diversos métodos de inteligencia artificial emplean corpus para entrenarse.
La gramática de constituyentes/transformacional en sus fundamentos teóricos no emplea predominantemente corpus, que es la llave en la que se basa el aprendizaje máquina para el procesamiento del lenguaje.
Por tanto, la unión de una falta de potencia de cálculo y del tipo de lingüística predominante hasta 1980 marcó el lento desarrollo del procesamiento del lenguaje natural.
Ejemplo
Si una persona española tuviera que pensar qué corpus emplear para el entrenamiento de un procesador de lenguaje natural en español, es fácil que centrara en las grandes obras literarias de nuestra lengua, como por ejemplo El Quijote, o un texto difundido en nuestra lengua, de amplia proyección, como puede ser La Biblia.
Lo mismo ocurre en otros idiomas, y en inglés en concreto, existe una base de datos que contiene un conjunto de corpus en esta lengua, que fue realizado en 2014 y recibe el nombre de Gutemberg.
En el siguiente link se puede ampliar información acerca de la base de datos Gutemberg: https://github.com/pgcorpus/gutenberg
En el link que aparece a continuación figura uno de los muchos corpus que pueden encontrarse para español: https://github.com/roquegv/spanishNLPModelCorpus
Por tanto, a la hora de llevar a cabo avances en el campo del procesamiento del lenguaje natural, es necesario disponer de un set de datos (o corpus) específico para cada lengua y, por consiguiente, existirán modelos específicos para cada idioma; todo ello determina el papel del lingüista en un proyecto de inteligencia artificial.
Tal como ya se ha estudiado, para que una máquina y un ser humano se comuniquen es preciso entender y estudiar la parte de la máquina y la parte del ser humano. Se iniciará este estudio comenzando por esta última, definiendo la lingüística y sus áreas principales.
Atendiendo a lo expuesto por D. Jurafsky en su texto «Speech and languaje processing», en el estudio de la lingüística de una lengua no solo es necesario llevar a cabo el estudio de las palabras y expresiones regulares del mismo, sino que es preciso estudiar las relaciones generadas por estos cuatro campos: morfología, sintaxis, semántica y pragmática.
La disciplina que hace uso de sistemas de computación para la compresión y la generación de lenguas naturales es la:
- Lingüística Computacional
- Ingeniería Lingüística
Un lingüista en un proyecto de inteligencia artificial aporta el conocimiento y el enfoque para llevar a cabo exitosamente la programación de las complejas estructuras (variables en virtud de los detalles de origen y evolución de cada lengua) entre los diferentes caracteres para formar una palabra, y de las diversas palabras para crear oraciones. Una clave de esta labor es el etiquetado, por el cual a una palabra, grafía, sintagma o estructura determinada se le asigna una etiqueta que lo clasifica.
Ejemplo
Perro es la combinación de las grafías «p» «e» «r» «r» «o», que a su vez desde un punto semántico representa el concepto de un animal, y cuya vocal «o» final denota el género de la palabra, que hace referencia al sexo del animal.
Dejando de lado conceptos técnicos más específicos, como el uso de N-gramas, expresiones regulares para la búsqueda de cadenas, transductores de estado finito, o modelos como el de cadenas ocultas de Markov, para el experto en inteligencia artificial (IA) es preciso tener un mínimo entendimiento de la parte realizada por el lingüista y, por tanto, conocer la esencia de estos campos:
-
Gramática: que incluye la morfología, la sintaxis y, para algunos autores, también la fonología.
-
Sintaxis: acorde al texto anteriormente citado de Jurafsky, estudia las reglas y principios que gobiernan la combinación de los constituyentes sintácticos. Analiza la formación de los sintagmas y las oraciones gramaticales. Mediante la sintaxis, se conocen las formas en que se combinan las palabras, así como las relaciones sintagmáticas y paradigmáticas existentes entre ellas. Como los sintagmas pueden unirse, para formar un grupo sintagmático, la sintaxis también establece la manera en la que llevar a cabo el proceso de unificación. En el etiquetado sintáctico se adjudica un POS (Part of Speech); por ejemplo, en español a la palabra mostrar se le asignaría la etiqueta POS de verbo, mientras que en la oración «el niño llora» se etiquetaría lo siguiente:
-
El
 Determinante.
Determinante. -
Niño
Nombre. -
El niño
Grupo sintagmático nominal. -
Llora
Verbo (y grupo sintagmático predicativo).
Por supuesto, dentro de una etiqueta pueden existir subcategorías, por ejemplo, «niño» es un sustantivo (nombre) de tipo «común» y «el» es un determinante de tipo «artículo».
Enlace
Existen herramientas web, como la que figura en el siguiente link, que llevan a cabo el etiquetado y la unificación: https://sintaxis.org/analizador/solucion/
- Morfología: según Jurafsky, estudia las reglas que rigen la flexión, la composición y la derivación de las palabras. Durante el etiquetado morfológico se determina la forma, clase o categoría gramatical de una palabra. El género de las palabras (masculino y femenino), el número de los nombres (singular o plural), o la persona de las formas conjugadas (primera, segunda o tercera) son ejemplos de este campo.
Enlace
El siguiente enlace presenta un analizador morfológico de la Biblioteca Virtual Miguel de Cervantes (BVMC) que usa el corpus Ancora.
-
Semántica: siguiendo el texto, estudia significado de las expresiones lingüísticas, es decir, las realidades que representan las grafías.
-
Pragmática: se centra en el análisis de la relación del lenguaje con los usuarios y las circunstancias de la comunicación o contexto. El contexto debe entenderse como situación, ya que puede incluir cualquier aspecto extra-lingüístico: la situación comunicativa, un conocimiento popular compartido por los hablantes, relaciones personales, y otros muchos.
RESUMEN:
- Morfología: El estudio de la información contenida en una palabra considerada ésta en el contexto en el que se utiliza.
- Sintaxis: Estudio de las relaciones estructurales entre las palabras en una frase. Estudio de cómo ordenar y agrupar las palabras en la frase.
- Semántica: Estudio de los significados de las palabras y su forma de combinarse para formar significados más complejos.
- Pragmática, Discurso: Estudia cómo el contexto afecta a la interpretación de las oraciones. El conocimiento inmersivo y exhaustivo de estos términos sus relaciones, y el etiquetado es labor del lingüista, y se lo debe proporcionar al experto en IA para una correcta modelización de un sistema de procesamiento del lenguaje natural, en un idioma concreto.
Aplicaciones del PLN¶
Algunas aplicaciones del PLN son:
- Reconocimiento automático del habla
- Traducción automática
- Sistemas de diálogo
- Extracción/recuperación de información
- Interfaces en lenguaje natural
- Herramientas para personas con diversidad funcional
- Ayuda a la redacción
- ...
Técnicas de procesamiento de lenguaje. Limitaciones¶
Potencial del procesamiento del lenguaje natural¶
Las aplicaciones del procesamiento del lenguaje natural son muchas: chatbots para el desarrollo de los asistentes de compra o sistemas conversacionales, análisis del sentimiento y de la opinión que permite detectar por las palabras empleadas sesgos y opiniones sobre un tema, especialmente en publicaciones de redes sociales, o en encuestas determinadas; clasificación automática de documentos, búsqueda de similitudes en textos para la búsqueda de plagios, detección de entidades (NER) que permiten contextualizar y clasificar textos, búsqueda automáti ca de información en múlti ples idiomas, traducción automática, reconocimiento del habla, y otras muchas.
Los aspectos fundamentales de las aplicaciones arriba mencionadas son los que se explican a continuación.
Reconocimiento del habla (ASR, Automatic Speech Recognition)¶
Disciplina encargada de convertir los fonemas emitidos por un ser humano en espectros de ondas de audio captados mediante un dispositivo de entrada de sonido de una máquina que, tras ser procesados dentro del contexto de un modelo lingüístico, den lugar a las grafías escritas del mismo; es decir, los sistemas de las máquinas encargados de convertir la voz captada por medio de un sensor (normalmente un micrófono) en la forma escrita de una lengua.
Síntesis de texto a voz (TTS, Text To Speech)¶
Estos sistemas hacen la labor contraria a un ASR, es decir, a partir de un texto escrito son capaces de reproducirlo mediante el dispositivo de salida de audio (altavoces).
Detección de entidades nombradas (NER, named entity recognition)¶
Consiste en trozear el texto (tokenizar) de tal manera que se detecten las palabras clave. Se trata pues de una labor de extracción de información que localiza y clasifica en categorías (normalmente personas, organizaciones, lugares, y cantidades) las entidades encontradas en un texto.
Traducción automática¶
Se centra en el desarrollo de sistemas capaces de traducir automáticamente texto o habla de un idioma a otro.
Similitud de textos¶
Algunos modelos (normalmente de tamaño considerable) han sido entrenados de tal forma que las palabras son etiquetadas de manera que aludan a conceptos semánticos.
Por ejemplo, un perro es un mamífero y a su vez es un animal. Un etiquetado correcto situará en lugares más próximos entre sí a un perro y a un gato (dos mamíferos) que a un perro y a un salmón. De la misma manera una manzana es una fruta, que a su vez es comida. En buena lógica es más «parecido» semánticamente a una manzana una naranja que una pata de pollo, aunque todo sea comida.
Mediante técnicas de vectorización y de cálculo del coseno es posible analizar dos textos y decir el «parecido» que tengan entre sí, aunque lógicamente esta apreciación de parecido es subjetiva y depende del set de datos que haya sido empleado para llevar a cabo el entrenamiento.
Análisis del sentimiento¶
El procesamiento del lenguaje natural puede emplear también el etiquetado característico del aprendizaje automático supervisado para entrenar un modelo, de tal manera que sea capaz de captar la positividad o negatividad de un texto en relación con un tema particular.
Esta potente herramienta es especialmente útil para llevar a cabo sondeos «invisibles» de la opinión de grandes grupos muestrales alrededor de un tema. Las redes sociales, y especialmente Twitter, conforman un campo de datos especialmente bueno para llevar a cabo este tipo de aplicaciones, ya que permiten analizar la opinión de un gran grupo de personas (por ejemplo, todo un país) alrededor de un asunto, o de una persona, lo que indirectamente se puede considerar un excelente sondeo de la opinión sobre la valoración de un político, o de un evento. También puede permitir a un asistente o chatbot, en una conversación larga, averiguar el estado de ánimo del usuario, y actuar en consecuencia.
Limitaciones. La ambigüedad¶
Una de las limitaciones mayores alrededor del procesamiento de lenguaje natural es la ambigüedad lingüística. Múltiples interpretaciones de una misma palabra pueden arruinar la capacidad de un sistema automático para responder correctamente y desarrollar su función. El etiquetado y el análisis visto en el apartado anterior ayuda a evitar este tipo de errores. Un ejemplo detallado para el español puede verse en el artículo de C. Zapata et al., de la Universidad de Colombia (Zapata, 2007). Los problemas de ambigüedad más comunes en los textos son los siguientes:
- Ambigüedad sintáctica: se presenta cuando una oración tiene asociada más de una representación sintáctica, es decir, si hay más de una regla gramatical representa dicha oración.
- Ambigüedad léxica/morfológica (gramatical): la primera ocurre cuando la duda surge respecto a un término aislado, que admite diversas interpretaciones. La segunda tiene lugar si una palabra que se encuentra en una oración representa más de un rol sintáctico o categoría gramatical dentro de la misma.
- Ambigüedad semántica: se presenta cuando afecta a un elemento de la frase que puede ser interpretado de diversos modos.
- Ambigüedad pragmática: aparece si la realidad depende del contexto del lenguaje y del hablante, en un momento dado.
- Ambigüedad fonológica: se presenta cuando una cadena de sonidos puede resultar confusa.
- Ambigüedad funcional: se observa si se emplea un término con doble función gramatical.
Ejemplo de Ambigüedades
-
Ambigüedad sintáctica:
Los perros y los gatos enfermos son recogidos por el servicio municipal de recogida de animales.
Se podría tener la duda de si son recogidos todos los perros y sólo los gatos enfermos, o si sólo los enfermos (ya sean perros o gatos). Compro los libros baratos. No se puede afirmar si los libros que estoy comprando son los baratos (adjetivo de libros) únicamente, o si estoy comprando libros, que resultan ser baratos (complemento predicativo): http://gedlc.ulpgc.es/investigacion/desambigua/morfosintactico.htm
-
Ambigüedad léxica/morfológica:
- Usted aquí no pinta nada (no se sabe si se refiere a que no tiene mando o a que no pinta por ejemplo una pared).
- Pedro y yo escribimos un cuento (no se sabe si lo hemos escrito ya o lo estamos escribiendo porque la forma conjugada puede pertenecer a un presente de indicativo o a un pretérito).
-
Ambigüedad semántica:
Pedro quiere pelearse con un italiano (no se distingue si se trata de cualquier italiano o de un individuo concreto).
-
Ambigüedad pragmática:
Golpeó el armario con el bastón y lo rompió (no se sabe si se rompió el bastón o el armario).
-
Ambigüedad fonológica:
«es»-«conde» (puede significar una forma conjugada del verbo esconder o el predicado del verbo ser y un título nobiliario).
-
Ambigüedad funcional:
He vuelto a oler (antes no tenía olfato y ahora sí; o bien, regresé a un lugar a oler algo para comprobar su aroma).
Desambiguación¶
La ambigüedad inherente al PLN es uno de los problemas presentes en todas fases del procesamiento de la lengua.
Ejemplos:
- Vino de la Rioja.
- Compré unos zapatos de piel de señora.
- La policía observó al sospechoso con unos prismáticos.
- El pescado está listo para comer.
- El cura recibió una cura en su habitación.
- Juan vio a Pedro enfurecido.
- Antonio no nada nada.
- No puedo ir a la fiesta porque no traje traje.
- Estaré de vacaciones solo unos días.
- El Villareal le ganó al Valencia en su campo.
- Me quedé esperándote en el banco.
POS Tagging¶
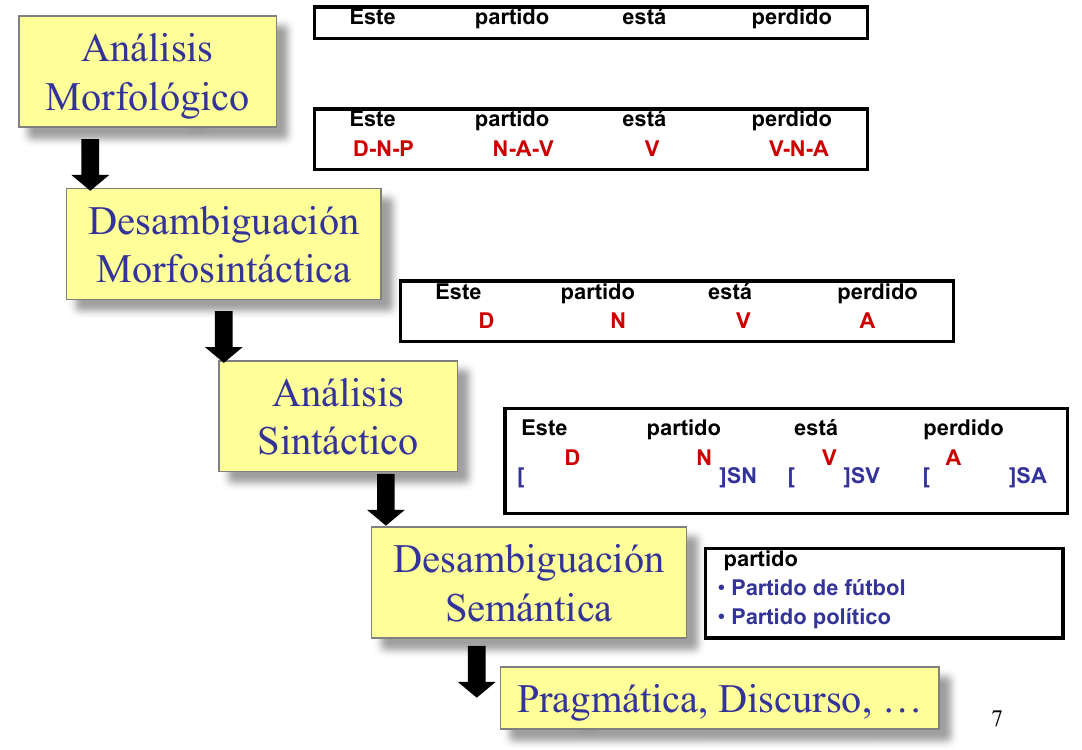
El POS Tagging (Etiquetado morfológico, etiquetado léxico, desambiguación morfosintáctica, ...) es el proceso de asignar, a cada una de las palabras de un texto, la categoría gramatical (POS: part-of-speech), sin tener en cuenta sus relaciones sintácticas. Las palabras, tomadas en forma aislada, en general, son ambiguas respecto a su categoría. La categoría de la mayoría de las palabras se puede desambiguar dentro de un contexto.
Ejemplo
- "Mételo en ese sobre" nombre
- "Déjalo sobre la mesa" preposición
- "Dame lo que te sobre" verbo
Categorías Gramaticales (POS)¶
La elección del conjunto de etiquetas afecta a la dificultad del problema. Hay que llegar a un equilibrio entre:
- Obtener la mayor información posible (etiquetas más específicas)
- Simplificar el trabajo de desambiguación (etiquetas más generales)
Tipos categorías
- Abiertas o Cerradas
Principales Categorías
- Nombres (comunes y propios)
- Pronombres (posesivos, interrogativos, ...)
- Determinantes (artículos, demostrativos, ...)
- Adjetivos
- Verbos
- Adverbios
- Preposiciones
- Conjunciones ...
Ejemplos de Etiquetas (POS)
- Penn Treebank: 45
- Brown Corpus: 87
- Susanne: 350
- LexEsp (PAROLE): 250
Conjunto de etiquetas Penn Tree Bank
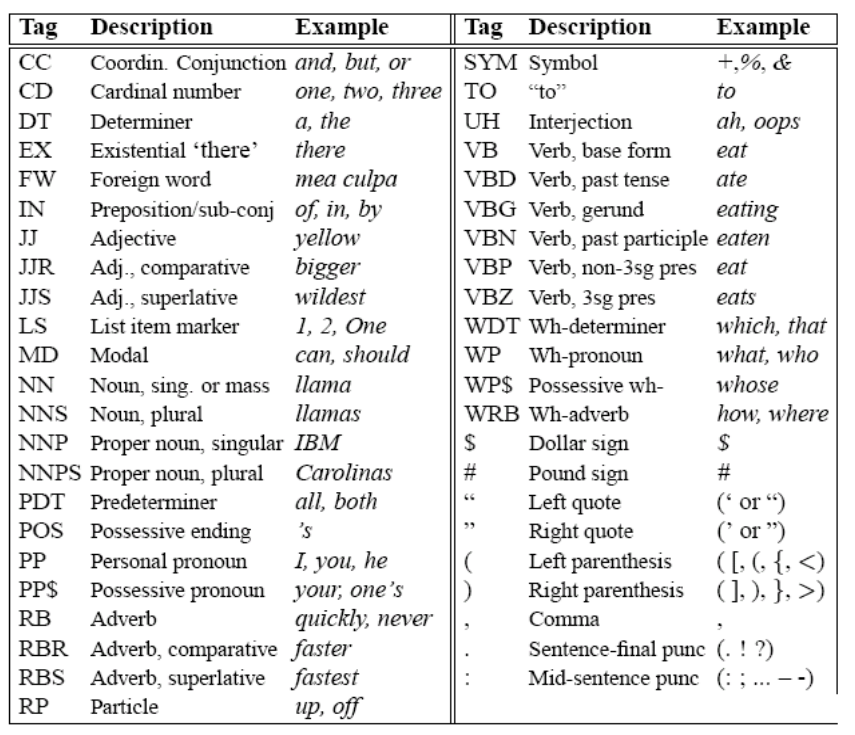
Conjunto reducido de etiquetas Parole

Formación del investigador en PLN¶
Un experto en sistemas de inteligencia artificial que desee adquirir conocimientos en procesamiento del lenguaje natural puede seguir muchos itinerarios. El aquí propuesto es una ruta tradicional, basada en una primera formación teórica y clásica, y una posterior aplicación de los métodos de procesamiento del lenguaje natural basados en redes neuronales. Por ello se aconseja la lectura del texto de Jurafsky, y posteriormente la lectura del manual base del Natural Learning ToolKit (NLTK) en lengua inglesa. A partir de ahí, continuar con Spacy en lenguas inglesa y española, y finalmente dar el paso a nVidia NeMo para ejecución de ASR, TTS y NLP en plataformas jetbot y posteriormente crecer a un entorno de servidores tipo JARVIS/TRITÓN.
- NLTK: puede ser descargado desde el portal web propietario https://www.nltk.org/ y a partir de ahí leer las instrucciones de instalación https://www.nltk.org/install.html, que son muy simples, y descargar los sets de datos mediante el comando
nltk.download(all)dentro del entorno de Python 3 (y tras ejecutar el import correspondiente). Incluso puede instalar el Stanford CoreNLP API para NLTK desde https://github.com/nltk/nltk/wiki/Stanford-CoreNLP-API-in-NLTK que incluye modelo para nuestra lengua. Dentro de NLTK debería seguir el orden lógico que se muestra en el NLTK-BOOK público (disponible en https://www.nltk.org/book/): - Cargar un corpus.
- Usar expresiones regulares.
- Tokenizar y etiquetar.
- Emplear lo anterior para hacer etiquetado POS.
- Usar diccionarios de eliminación de stop-words.
- Usar N-gramas.
- Lematizar.
- Programar un clasificador (por ejemplo, de películas según temática o de noticias).
- Programar un comparador de textos.
- Programar un analizador de sentimientos.
- Programar un sistema de ideas clave o resumen.
- Emplear un TTS (no desde NLTK).
- Emplear un ASR (no desde NLTK).
- Programar un procesador semántico real.
- Spacy: puede ser descargado e instalado siguiendo las instrucciones de https://spacy.io/. En él se debería practicar lo anterior, además de:
- Vectorización y comparativa por vectorización a partir de modelos pre entrenados disponibles en el programa como los empleados en este texto.
- Lo mismo con otros modelos entrenados, como variaciones de BERT.
- Generar un modelo propio de vectorizado por etiquetación, con un set muy cerrado, de tal manera que las similitudes sean más específicas al texto que se esté tratando.
- NER, y análisis morfológico con visualización de grafos a través de displacy.
- Traducción entre idiomas.
- NeMo: ha de ser empleado de manera global para NLP, TTS y ASR siguiendo los tutoriales y ejemplos de su GitHub, destacándose entre otros, los siguientes:
- ASR:
- Detección de voz (Voice activity detection) a través de micrófono
- Voz a Texto en PC x86, offline.
- Voz a Texto en PC x86, online.
- Voz a texto en Jetbot.
- Comandos de voz (la base para un asistente).
- TTS.
- NLP:
- Lo mismo que en Spacy.
- Uso del modelo de Megatron.
- Programar un Q&A tipo Jeopardy.
- jetson-voice: es una biblioteca de inferencia de aprendizaje profundo ASR/NLP/TTS para Jetson Nano, TX1/TX2, Xavier NX y AGX Xavier. Es compatible con Python y JetPack 4.4.1 o posterior. Los modelos DNN se entrenaron con NeMo y se implementaron con TensorRT para optimizar el rendimiento. Todos los cálculos se realizan utilizando la GPU integrada. Actualmente se incluyen las siguientes capacidades:
-
Reconocimiento automático de voz (ASR)
- Transmisión ASR (QuartzNet)
- Reconocimiento de comandos/palabras clave (MatchboxNet)
- Detección de actividad de voz (VAD Marblenet)
-
Procesamiento del lenguaje natural (PNL)
- Clasificación de intención conjunta/espacio
- Clasificación de texto (análisis de sentimiento)
- Clasificación de tokens (reconocimiento de entidad nombrada)
- Preguntas/Respuestas (QA)
- Texto a voz (TTS)
Elaboración de un sistema de procesamiento de lenguaje orientado a una tarea específica¶
Se propone aunar todo lo aprendido en la generación de un código que tras adquirir vía ASR la conversación de un usuario con un robot de cocina, sea capaz de hacer que este funcione, teniendo en cuenta las siguientes limitaciones:
- El robot puede cocinar mediante calor (cocer). Esta operación requiere de una temperatura en grados Celsius y de un tiempo expresado en minutos, hasta un máximo de 120 °C.
- El robot puede preparar alimentos agitando un instrumento, como por ejemplo batir o remover algo (batir). Esta operación requiere de una velocidad expresada en un valor del 0-10 y de un tiempo expresado en minutos, hasta un máximo de 120.
- El robot puede parar (lo cual implica velocidad de giro 0, temperatura 0 °C, tiempo 0).
- El robot ha de poder entender frases alternativas, es decir, en lugar de batir, emplear el verbo remover, o agitar, o uso de verbos generales como «pon el robot a velocidad 5».
- El robot ha de poder entender frases compuestas, que especifiquen en un solo comando temperatura, velocidad y tiempo.
El abordaje de esta labor es sencillo:
- Un ASR convierte la voz a texto.
- El texto es procesado:
- Se quitan las palabras inútiles (stop words).
- Se unifican mayúsculas, minúsculas y signos.
- Se tokeniza y se etiqueta.
- Se localizan los tokens correspondientes a verbos de acción (cocer, batir).
- Se localizan los tokens correspondientes a valores numéricos.
- Se va haciendo agregación sintagmática.
- Se activan las salidas en una GPIO.
Ejemplo
Puede emplear los contenedores de nVidia para, mediante Docker, emplear NeMo sobre un sistema operativo Ubuntu con gran facilidad.
NLTK y Spacy son librerías simples pero muy eficaces para trabajar con los aspectos informáticos principales del lenguaje natural, si bien NeMo es una solución mucho más potente capaz de llevar a cabo labores TTS y ASR.
El reconocimiento de entidades nombradas (NER), el tokenizado, y el etiquetado son instrumentos básicos a la hora de descomponer un texto y extraer la información más relevante.
En el reconocimiento del lenguaje natural, además de la figura del técnico, ha de existir una figura asociada al lingüista.